Last week the working group chairs in charge of developing the code of practice for providers of General Purpose AI models published the third draft of the code for comments and feedback. This is again a significant evolution of the language of the 2nd draft. And while there are some improvements on substance (especially for developers of open source AI models), overall the ambitions of the copyright chapter have been toned down quite a bit. In this context we find a rather curious limitation that reduced the scope of the requirement “to put in place a policy to comply with Union law on copyright and related rights” to a set of commitments that mostly only deal with data obtained by “crawling the World Wide Web”.
Before we look at issue in detail here is a quick overview of the main substantive changes in the third draft:
- The new draft deletes all KPIs related to the individual measures (this is a CoP wide change so not specific to the copyright provisions).
- The public disclosure measures related to the copyright policy are watered down: Signatories encouraged, but no longer commit, to make any compliance information publicly available.
- A new commitment to not circumvent technical protection measures replaces the previous commitment to ensure lawful access, which is a significant improvement related to one of the most problematic points on the previous draft.
- The commitment to make best efforts to prevent copyright overfitting has been replaced with reasonable efforts “to mitigate the risk that a model memorizes copyrighted training content to the extent that it repeatedly produces copyright-infringing outputs”. This is a significant improvement of another highly problematic aspect of the 2nd draft.
- The new draft also contains a big improvement for developers of open source AI models as there is no more requirement to have an acceptable use policy or to contractually limit any uses that are allowed by law. Open Source AI models are now explicitly excepted from the commitment to take measures to prohibit copyright-infringing uses.
But things get a bit strange when it comes to the two measures on rights reservations compliance. These measures have been significantly rewritten in response to feedback to the 2nd draft and, while some of the problematic aspects have been resolved, the Chairs have made a rather curious design choice. They have decided to limit the commitments to comply with rights reservations expressed in line with article 4(3) of the CDSM directive to training data that has been obtained by “crawling the World Wide Web”. This means that training data that is being obtained via any other way is not covered by the code of practice:
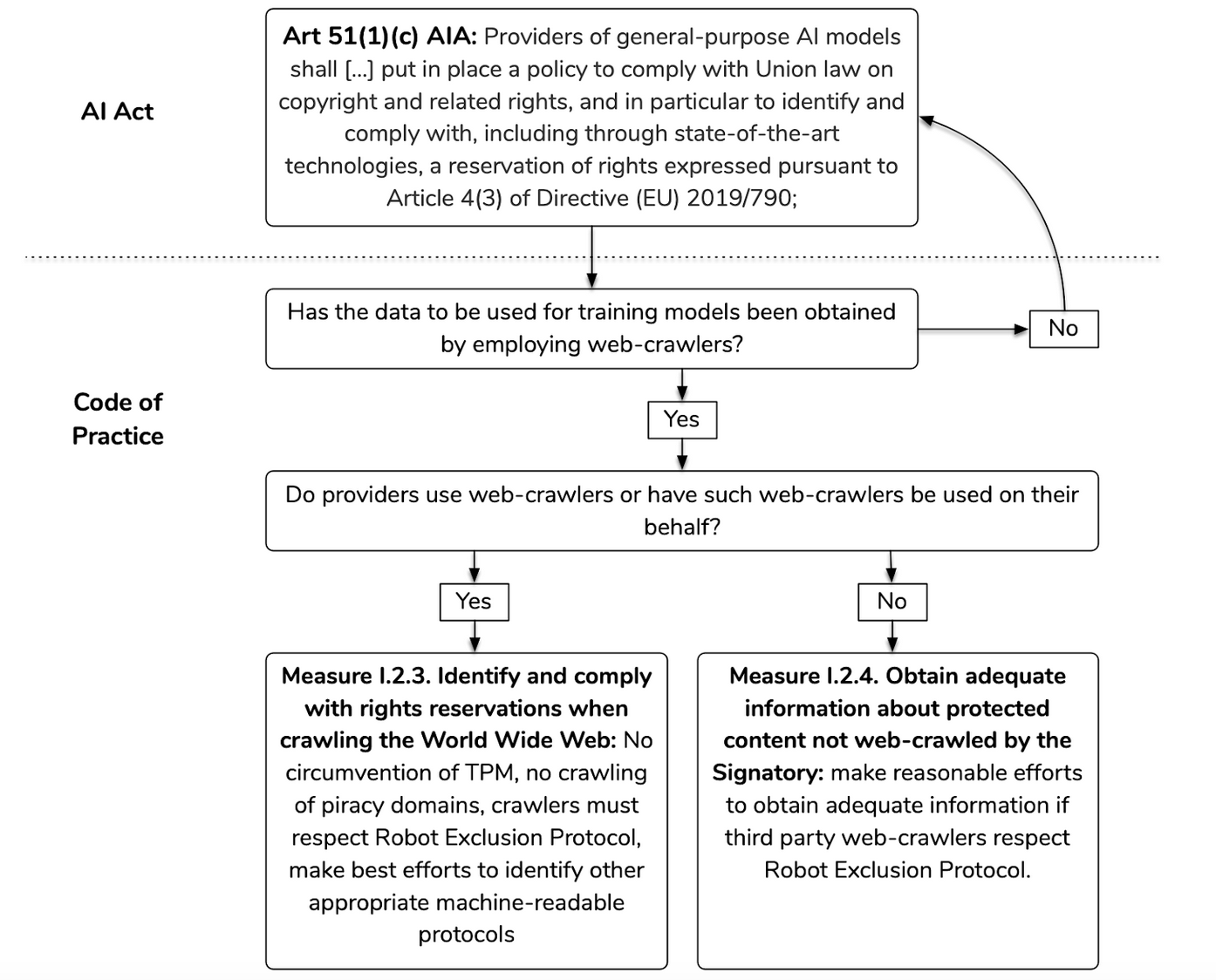
This limitation has some rather curious and probably unintended effects. For example, the requirement to make reasonable efforts to exclude piracy domains from web-crawling would not cover a scenario like Meta’s documented use of bit-torrent to download large books data sets that included large numbers of pirated books. Using bittorrent is something different from web-crawling, and while this example might be extreme there are many other ways to obtain data online that are not web-crawling and thus fall outside of the commitments contained in the code of practice.
It is not evident why the Chairs have chosen for this limited scope of the measures related to rights reservation, especially since art 53(1) point(c) does not establish a special regime for web-crawling but rather contains a requirement to put in place a policy to comply with Union copyright law, which has implications for the use of copyright-protected works no matter how they are acquired by model providers.
As we have argued in our recent policy brief on a vocabulary for AI training opt-outs, reducing the issue of respecting rights reservation to a narrow web crawling context, does not make sense. Web crawling is just one of many data acquisition strategies for AI model developers. The real concerns that need to be addressed by a copyright policy arise in relation to the use of the acquired data for the purpose of training (generative) AI models.
As a key element of the EU regulatory approach to the training of AI models, the code of practice should recognize this.





