Timeline

This study evaluates CommonsDB's transition from design to deployment, testing the registry's real-world performance with live data from partners.
The OLG Hamburg ruled that machine-readable opt-outs must be machine-actionable, not just intelligible—but it left the definition of standards to ongoing fragmentation.
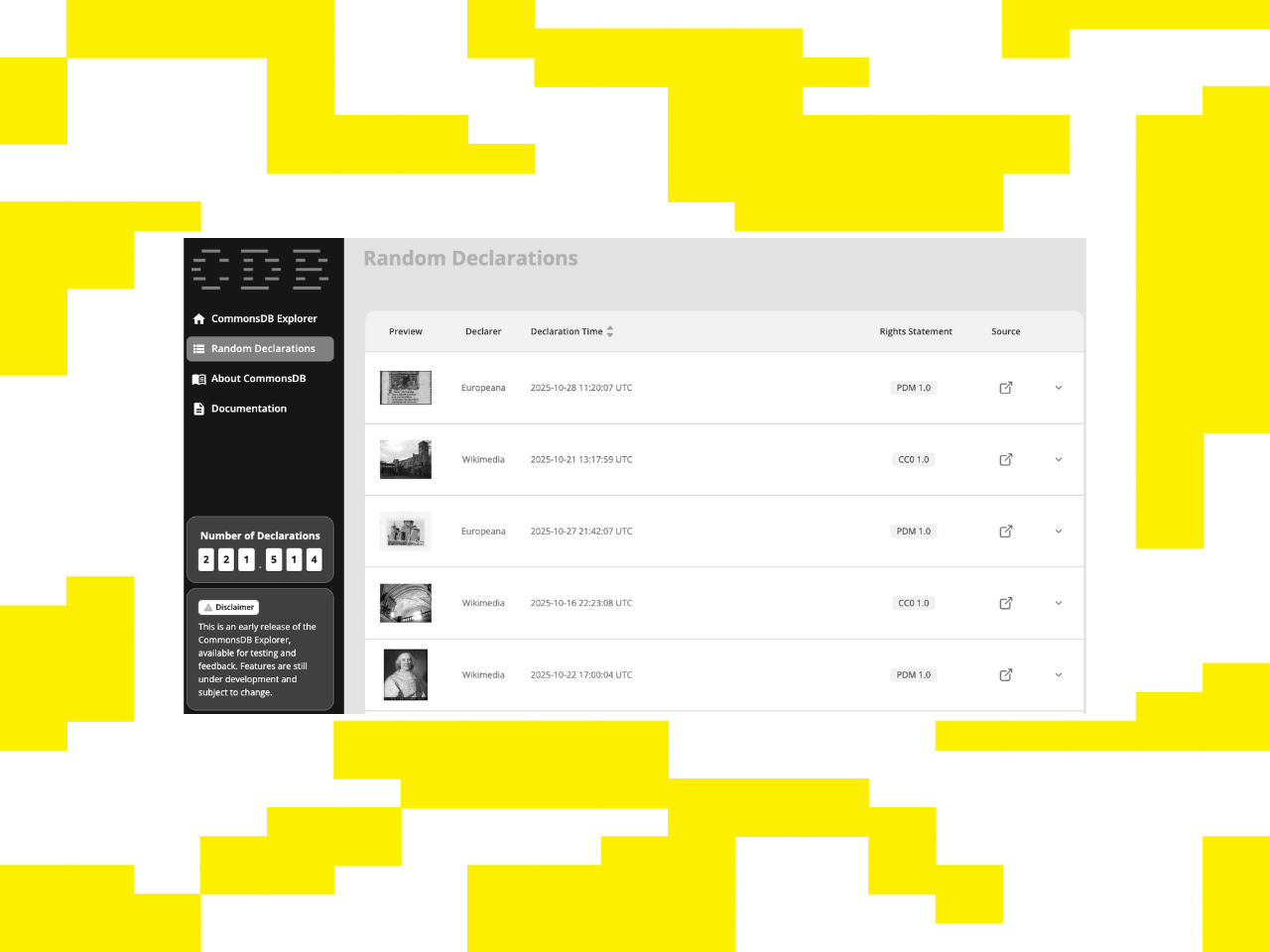
CommonsDB Explorer demonstrates how verifiable rights information can be shared across systems, providing clearer and more reliable rights information for cultural heritage institutions and platforms.
This study outlines how CommonsDB is creating a registry of Public Domain and openly licensed works to improve legal certainty when reusing digital content.

Open Future launches the CommonsDB initiative to create a prototype registry of public domain and openly licensed works. The registry will enable users to verify the rights status of content from multiple sources.
Every year in January, Open Knowledge and Open Culture communities celebrate the moment when heritage works enter the Public Domain, as their copyright terms expire. Open Future participated in this year’s celebration of Public Domain Day 2025, which took place on January 9 at the Royal Library of Belgium (KBR). Professor Séverine Dusollier (University Professor […]
Observations on the hearing of the first court case dealing with the use of copyrighted works as AI training data in the context of the European Union's copyright framework.
This policy brief explores what compliance policies for Article 53(1c) of the AI Act could look like in practice and what technical standards and services are available to implement the rightholder opt-outs.
In a recent article titled 'Generative AI Has a Visual Plagiarism Problem', Gary Marcus and Reid Southen provide further evidence of the ability of generative AI models to reproduce remarkably similar versions of works in their training data. They show that, in response to generic prompts, the latest versions of Midjourney and dall-e return images that closely resemble frames from popular movies and/or contain copyrighted characters. This discovery raises a number of interesting questions about the ability of these models to infringe copyright - seemingly on their own.
The article is also notable for a quote from David Holz, founder and CEO of Midjourney in response to a question about whether Midjourney seeks permission from copyright holders. His answer:
No. There isn’t really a way to get a hundred million images and know where they’re coming from. It would be cool if images had metadata embedded in them about the copyright owner or something. But that’s not a thing; there’s not a registry. There’s no way to find a picture on the Internet, and then automatically trace it to an owner and then have any way of doing anything to authenticate it.While this response sounds derisive in the context of the article (a similar statement made by Open AI to the House of Lords was also criticized as derisive), Holz does have a point. There is indeed an urgent need for better copyright information infrastructures that allow AI model developers and others to automatically assess the copyright status of works - and clear rights. Something we pointed out in our recent policy paper on best practices for opting out of ML training and an earlier white paper on a public repository of public domain and openly licensed works.

The blog post argues that with increasing convergence on creator/rightholder opt-outs as an essential mechanism in the governance of generative AI models, there is an urgent need for standardization of machine readable opt outs.
This Open Future policy brief examines the technical implementation of the EU law provision allowing authors and other rightholders to opt out of having their works used as training data for (generative) machine learning (ML) systems.

In the 2023 budget, the EP allocated funding for a pilot project to explore the feasibility of a Public EU directory of works in the public domain and under free licenses, something that Paul Keller and Felix Reda suggested in a white paper in 2021.

White-paper on how to to leverage Article 17 of the Copyright in the Digital Single Market directive to build a public repository of Public Domain and openly licensed works.




