A vocabulary for opting out of AI training and other forms of TDM
This policy brief presents a proposal for a vocabulary for opting out from AI training and other forms of Text and Data Mining (TDM). The proposal contained in the policy brief answers to one of the recommendations that we made in our previous policy brief on Considerations for Implementing Rightholder Opt-Outs by AI Model Developers that we published last May.
The new policy brief consists of two parts: (1) a proposal for a vocabulary for opting out from AI training and other forms of text and data mining in (Annex 1) and (2) a paper that elaborates on the process of coming up with the vocabulary.
The vocabulary that we are presenting today has been developed based on extensive interactions with opt-out systems providers, rightholders, AI model providers, and other public interest technology groups. Both the vocabulary and the policy brief reflect the position of Open Future only – which is based on our best understanding of issues at play in a highly contested space. We are publishing this paper and vocabulary to contribute to ongoing debates and to facilitate the development of robust, interoperable standards for machine-readable rights reservations on copyrighted works used for AI training.
Why a vocabulary?
As we have argued in our previous policy brief, having a common vocabulary for machine-readable opt-outs is a necessary first step towards a set of robust and interoperable machine-readable opt-outs standards that are effective, scalable, and able to meet the needs of both rights holders and AI model developers.
There is currently a multitude of systems that allow creators and other rightholders to make machine-readable rights reservations/opt-outs which creates uncertainty both on the side of rightholders (who need to make decisions about how to express machine readable opt outs) and AI model providers (who need to determine how to comply with opt-outs expressed via a multitude of systems).
In this situation the purpose of a common vocabulary is to define a set of standardized use cases that can be used by providers of opt-out standards to describe the scope of statements of rights reservations and opt-outs. This would result in a basic level of interoperability between all opt-out systems that adopt the vocabulary.
The vocabulary
The vocabulary proposal published today in Annex 1 of the policy brief is relatively straightforward. It consists of three defined categories that are nested in each other:
The overarching category is ‘Text and Data Mining’ which is defined in line with the definition in the European Union’s Copyright in the Digital Single Market Directive. Within this category we situate the ‘AI Training’ and within this category we situate the ‘Generative AI Training’ category.
The vocabulary also leaves space for additional use cases to be defined in the future.
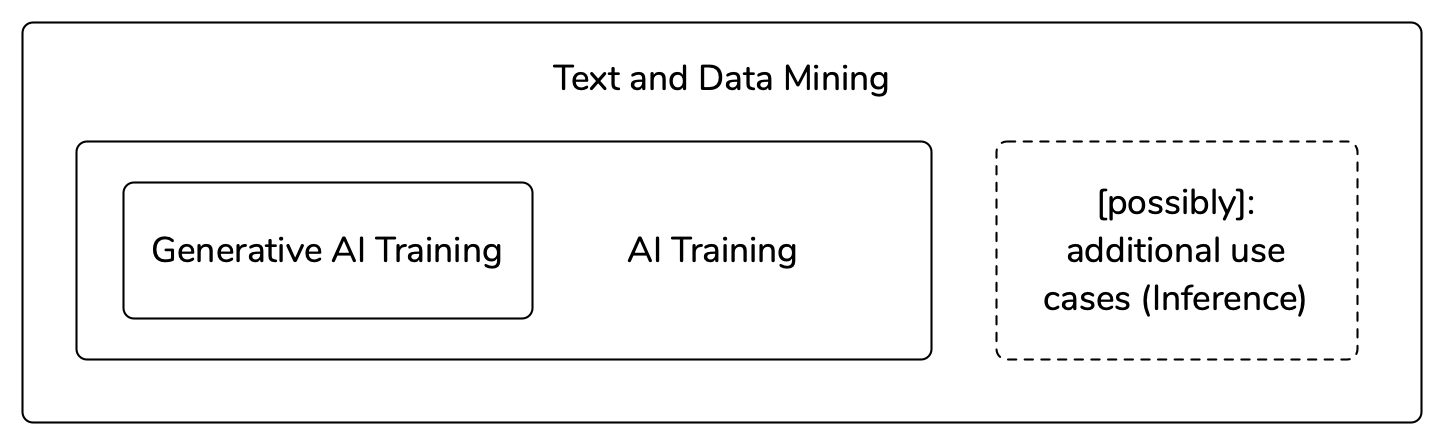
High level overview of the structure of the proposed vocabulary
By selectively targeting one of these categories, opt-out systems can enable opt-outs ranging from a full TDM rights reservation to a much more targeted opt-outs that exclude the use of the opted out works only from training those AI models that are capable of generating synthetic content.
We hope that even with this relatively modest scope and relatively abstract level of application, the proposed vocabulary will contribute to the emergence of a set of robust and interoperable machine-readable opt-outs standards that are effective, scalable, and able to meet the needs of both rightholders and AI model developers.






