As in many other places, the abrupt removal of access to Anthropic’s Fable model has caused a lot of hand-wringing about dependency on US frontier AI models in the Netherlands. What makes the Dutch discussion noteworthy is that for some commentators, the news has been a reason to publicly bash the presumed performance of the main Dutch attempt to build sovereign AI: the GPT-NL project.
This project, run by TNO and a number of public-sector partners, was launched in 2023 with the ambition to build a rights-respecting large language model trained on high-quality Dutch content.
The project has gained a lot of attention, in large part because of a number of content deals the developers have made with rightholders—including a group encompassing the major Dutch news publishers. Yet its actual capabilities remain shrouded in mystery. The model is neither publicly available nor has anyone with access described its performance on the record. The level of secrecy surrounding the model has made it easy to dismiss its capacity in public.
This in turn has led other observers to defend GPT-NL on the grounds that it is a principled attempt to build an AI model based on public values including “respecting copyright, compensating and sustaining our media organisations and heritage institutions, preserving/restoring a healthy information ecosystem, and preventing exploitation in how data and models are maintained” (own translation). As I have argued before these are very relevant concerns and one of the reasons why Europe needs to build a public AI ecosystem. But what if “respecting copyright” as it is understood by GPT-NL is simply incompatible with both the ambition to build usable AI models and ensuring the sustainability of the information ecosystem at large? As it turns out, the project offers some valuable insights that can help answer this question.
GPT-NL ❤️ rightholders
So what does GPT-NL mean when it says its approach is based on respecting copyright? The answer goes well beyond respecting copyright law. It comes closer to building a data sourcing policy around a set of rules that resemble how many rightholders would prefer copyright law to be. GPT-NL trains only on data it has positive authorization to use: public-domain and openly-licensed content, public-sector data, and in-copyright material licensed directly from rightholders under negotiated agreements. This opt-in/licensing-only approach means that GPT-NL abstains, in principle, from using data crawled from the open web and from Wikipedia.[1] This is not because copyright requires it, but a deliberate design choice. It makes GPT-NL the most rightholder-respecting LLM-building effort available.
Adopting this rightholder-aligned data sourcing strategy has allowed GPT-NL to bring on board a number of Dutch rightholders who have contributed their content for use as training data. The most prominent of these collaborations is the agreement with NDP Nieuwsmedia, the association of Dutch commercial news publishers, which brought in archives from most major Dutch news outlets under a single licensing arrangement. This agreement is one of the defining features of the project, but, as we shall see, it comes at a significant cost.
The cost of this choice is that GPT-NL forgoes most of the training data it could lawfully have used. Article 4 of the CDSM Directive permits text and data mining of lawfully accessible content for any purpose, including commercial AI training, subject only to rightholders opting out. A model built on that basis could draw on the open web, Wikipedia, and the vast body of digitized text whose rightholders have expressed no objection—exactly the material that makes up the bulk of any competitive training corpus. And it is not only a matter of volume: the open web is also where the diversity of domains, registers, and topics lives, the breadth that licensed news archives and public-sector records, however large, cannot supply on their own. Given that both the volume and the diversity of training data are central to model quality, this represents a significant constraint on what GPT-NL can achieve.
Does respecting copyright break the model?
Until now, this tradeoff has been difficult to quantify due to the fact that GPT-NL is not yet publicly available.[2] However last week Edwin Rijgersberg, who until September 2025 was the NFI’s project leader for GPT-NL, published a blogpost analyzing a set of benchmark results that had been quietly published by TNO in a technical document in late 2025. In his analysis, he uses these benchmark results to compare GPT-NL’s performance against the models the project has used as reference points (GPT-3.5 and Llama 2 7B) and a recent European open source model (Mistral Small 3.2). The resulting picture is not pretty: On all four Dutch-language indicators, GPT-NL, a model built specifically for Dutch, is beaten by at least two of the three other models, none of which had any Dutch-specific training objective. On one of the indicators, factual knowledge, the gap is dramatic: GPT-NL scores barely above what random guessing would produce.
Rijgersberg’s post sets out to assess GPT-NL’s capacity as a usable sovereign alternative, and while he repeatedly attributes its weak performance to the project’s restrictive data sourcing policy[3], isolating the effect of that policy is not his aim. To see how far the copyright policy is actually responsible, we need a different comparison.
The comparison we need is with a model that takes copyright compliance seriously too, but stops short of GPT-NL’s self-imposed abstention. The Swiss Apertus model[4], released in September 2025, fits the bill: its technical report is unusually detailed about how the training data was selected, and it goes as far as retroactively filtering its web crawl for opt-outs to comply with the EU copyright directive. The crucial difference is that Apertus does not refuse the open web on principle—it relies on the text and data mining exception and removes only the content that rightholders have actually opted out of.
Apertus’s scores on the same benchmarks Rijgersberg used are available in EuroEval[5]. The chart below sets the results for Apertus-8B base alongside his numbers[6]:
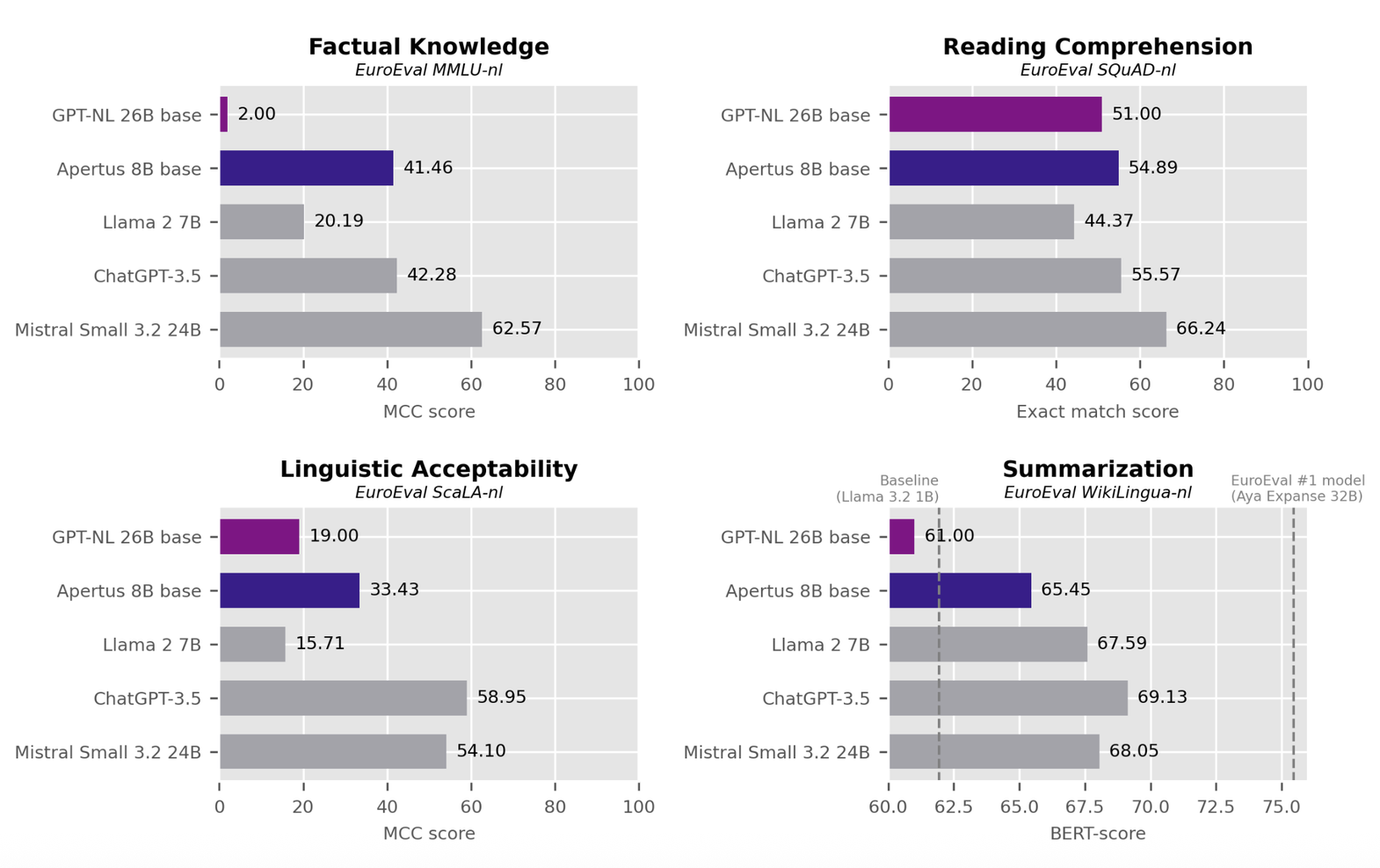
The result is unambiguous. On the four benchmarks in the table, Apertus-8B base outperforms GPT-NL across the board. On factual knowledge, where GPT-NL barely clears random guessing, Apertus scores 41.46, roughly on a par with GPT-3.5. On summarization, GPT-NL is at the floor[7] while Apertus clears it. On reading comprehension and grammatical acceptability, Apertus is comfortably ahead as well, and it does so as a smaller model with no Dutch-specific training objective[8].
It is important to note that this is not a controlled experiment. Apertus also has a larger and differently composed training corpus, and the two models differ in other ways, so these numbers establish a correlation, not a clean causal claim. The comparison above cannot rule out that something other than data sourcing explains the gap, but the direction is hard to argue with: the more permissive model is smaller and still wins across the board. Apertus illustrates that respecting opt-outs at scale does not make building a usable model impossible.
What separates the two is that Apertus uses the data the law allows, while GPT-NL declines most of it, and the model that uses more of it wins on every measure. While these numbers cannot prove that abstention alone explains the gap, they make clear that it is GPT-NL’s self-imposed, rightholder-aligned stance—not copyright compliance as such—that is holding the model back.
But will rightholders actually get paid?
Now, GPT-NL has never claimed to be building the best-performing system, and it is important to acknowledge that it still does the thing its proponents praise: it has arrangements with rightholders intended to establish a different set of rules. Rules that support the information ecosystem, in contrast to the prevailing practice of training on publicly available information without any return to those who produce it.
Setting the model’s performance aside, the real question that matters to the rightholders who contributed is: will they be paid?
The answer depends on how the deal is structured. According to the information that is publicly available[9], the participating publishers have entered into a revenue-sharing arrangement: rather than being paid at training time for the use of their content, they receive no payment upfront and instead share in the revenue the model earns once it reaches the market.
A revenue share is only worth as much as the commercial success of the model it is tied to. If GPT-NL cannot build a system that competes—and so far the benchmarks suggest it cannot—then their 50% share of its licence revenue, however generous it sounds, amounts to 50% of next to nothing. The difficulty in assessing a model’s commercial potential upfront is one of the reasons we, among others, have argued for a levy that attaches to the revenue generated by all commercial deployments of models trained on publicly available information.
So far, such proposals have been met with opposition from rightholders, which makes it all the more striking that, as a mechanism, the GPT-NL arrangement and these levy proposals are very similar. The GPT-NL revenue-sharing mechanism is already levy-shaped in its architecture—a pooled fund, distribution by a usage-based key, payment triggered by deployment revenue—even if the base it rests on is too narrow to make it work. The most copyright-respecting project on offer has, in effect, reinvented a levy by contract. The one thing a contract cannot do is make participation mandatory—and it is precisely the large commercial model developers, who would never enter an arrangement like this voluntarily, that generate the revenue that would make such a system worth running.
Widening the base
The difference then is not in the redistribution mechanism but in its legal basis—and that difference is the whole point. GPT-NL keeps the exclusive-rights, opt-in architecture that rightholders prize: nothing is used without a licence. A levy gives up the exclusive right at the point of training and replaces it with a remuneration right. That sounds like the larger concession, but it is what makes the difference in outcome: an opt-in deal can only ever reach the revenue of the models whose developers agree to license, while a remuneration right reaches deployment across the market, including the high-revenue commercial models whose developers decline to license. Giving up the right to say no to any individual model developers is what buys access to a share of the revenue of all of them.
There is a second sense in which the licensing route is too narrow. A deal can only ever pay those who hold exclusive rights and have the bargaining power to negotiate. In practice, that means the handful of large, organized rightholders in any given sector—the major news publishers in GPT-NL’s case—while the long tail of individual creators, whose work is just as much in the training data, has no realistic way to strike a deal and falls outside the arrangement entirely[10].
But the data AI models are built on is not limited to licensed news archives. It draws on the public domain, openly licensed content, public-sector information, and the holdings of cultural heritage institutions—most of which have no rightholder to license it and no one positioned to strike a deal. Because a remuneration right attaches to deployment rather than to the act of licensing at training time, its proceeds can (and should) be distributed more widely: not only to rightholders, but to the public-interest media, cultural heritage institutions, open content platforms, and public AI infrastructure that produce and maintain the information commons these models depend on. A levy sustains the wider ecosystem that produces the training data in the first place: the ecosystem GPT-NL’s proponents say they are trying to protect.
Towards sustainable European AI
Let us return to where this piece began. The dependency anxiety shaping the debate about sovereign European AI is real. The approach embodied by GPT-NL gets something important right about what a European alternative must attend to—the health of the information ecosystem as a whole—but it just as clearly shows that the method it chose is not suited to achieving that goal. Artificially limiting access to data may be sympathetic to rightholders, but it ultimately neither benefits them nor helps build competitive models.
The alternative is to accept the reality that competitive models need to be trained on as much information as possible, and that this includes web-crawled data. Being trained on the sum total of publicly available information is one of the defining features of current development approaches, and refraining from using such data—however well-intended—is simply not a viable option. A deployment-based levy with broad redistribution is a mechanism that acknowledges this reality without giving up on the objective of supporting the creators, producers, and stewards of that information.
But such a levy isn’t only a fairer way to support information producers. A deployment-based levy would, in effect, replace the opt-out in Article 4 with a non-waivable remuneration right—giving European developers the same friction-free access to training data that their non-European competitors already operate under, while guaranteeing the ecosystem a share of the revenue that use generates. It strips out the friction and chilling effects that currently hold back model development in the EU. And, as I have argued here, it preserves room for exclusive licensing of copyrighted works at inference time, where rightholders retain real leverage.
Learning from GPT-NL
GPT-NL’s prospects as a viable sovereign model may be doubtful, but the project has been genuinely instructive. In trying to do the right thing—to build on a consensual, rightholder-respecting basis—it has shown us two things at once. First, that abstaining from the data the law allows produces a model that cannot compete; and second, in the structure of its own remuneration deal, what supporting the information ecosystem actually looks like in practice. Even this maximally consensual route reinvents the collection-and-distribution architecture of a levy—but, tied to the fortunes of a single licensed model, it can never reach the revenue across the market that would make such a system worth running. Only a statutory base can do that.
The lesson is not that GPT-NL aimed at the wrong goal, but that the goal is unreachable by the means it chose. Building sovereign European models and sustaining the ecosystem that feeds them are not competing objectives—but achieving both at once requires giving up on copyright as a right to refuse, and rebuilding it as a right to be paid.
This analysis was first published in two parts on Kluwer Copyright Blog: part 1 and part 2.

Footnotes
- The exclusion of Wikipedia is difficult to understand. All of the Dutch language wikipedia, easily the most comprehensive body of high quality Dutch text available opting out line is licensed under the CC attribution share alike license which explicitly authorises re-use. The decision not to use Wikipedia is driven by an assumption that the Share Alike clause might require them to release the trained models as open source. This assumption is almost certainly not true since the ShareAlike mechanism doesn’t reach model weights (see Senftleben and Szkalej (2024))^
- According to the project, GPT-NL is currently in closed testing. As of its February 2026 progress report, the model had entered a pilot phase with five launching customers from the Dutch public sector, with broader availability planned for the second half of 2026^
- Rijgersberg puts GPT-NL’s Dutch training data at under 55 billion tokens—only around 10% of the total. To put that in perspective, he notes that the EU-funded HPLT v3.0 web-crawl dataset alone—which was not used in line with the data sourcing policy—contains over 150 billion Dutch tokens.^
- Apertus is a large, fully open language model released in September 2025 by a Swiss public consortium (EPFL, ETH Zürich and the national supercomputing centre CSCS). Like GPT-NL it is a publicly-backed effort to build a sovereign, openly-developed model on a broadly copyright-respecting basis.^
- EuroEval Dutch leaderboard, (v16.10.1, retrieved 20 June 2026). ScaLA-nl (MCC) and SQuAD-nl (EM) from the NLU view; MMLU-nl (MCC) from the generative view. Rows: swiss-ai/Apertus-8B-2509 and swiss-ai/Apertus-70B-2509. The Apertus-8B WikiLingua-nl figure was provided by Edwin Rijgersberg, on the same metric as GPT-NL’s score.^
- Apertus comes in 8B and 70B versions, each with a base and an instruction-tuned variant. The 8B base model is the closest comparison to GPT-NL’s foundation model—a non-instruction-tuned base model—and at 8 billion parameters it is smaller than GPT-NL, so it cannot be winning on size alone.^
- Summarization is scored with BERTScore, which does not run from zero: scores cluster near the top, so a score of around 61 marks the practical floor (a small model that cannot summarize Dutch well). GPT-NL’s 61 sits at that floor; Apertus and the others score above it.^
- These are intermediate figures, taken after pre-training but before the small-scale instruction tuning GPT-NL still plans. As Rijgersberg notes, instruction tuning of that kind can usually squeeze a little more performance out of a model, but rarely shifts benchmark scores dramatically. The GPT-NL numbers should therefore be read as provisional and may still improve somewhat..^
- As noted by the Auteursbond, the participating news media receive no payment upfront and instead share in the proceeds if the model generates revenue. The Revenue Sharing Mechanism published by GPT-NL sets the contributors’ collective share at half of the net licence revenue.^
- This pattern is visible in the GPT-NL deal itself. The above referenced Auteursbond post notes that it remains unclear whether and how the journalists and other authors of the licensed content will be compensated under the GPT-NL / NDP agreement.^




