Late last week, the European Commission, the Member States, and the European Parliament reached a deal on the AI Act. Some of the details still need to be worked out between the co-legislators. Still, there is enough publicly available information[1] to allow a first analysis of how the AI Act — once implemented — will likely impact open source AI development.
This analysis builds on our earlier comments on the Council mandate from December 2022 and the Parliament’s position, adopted in June of this year. Unsurprisingly, the final compromise text is a mix between the two. It uses the Council’s terminology — the text refers to the “General Purpose AI models” instead of the “foundation models” that the Parliament proposed — but maintains the Parliament’s approach of imposing mandatory obligations defined in the Act on those models.
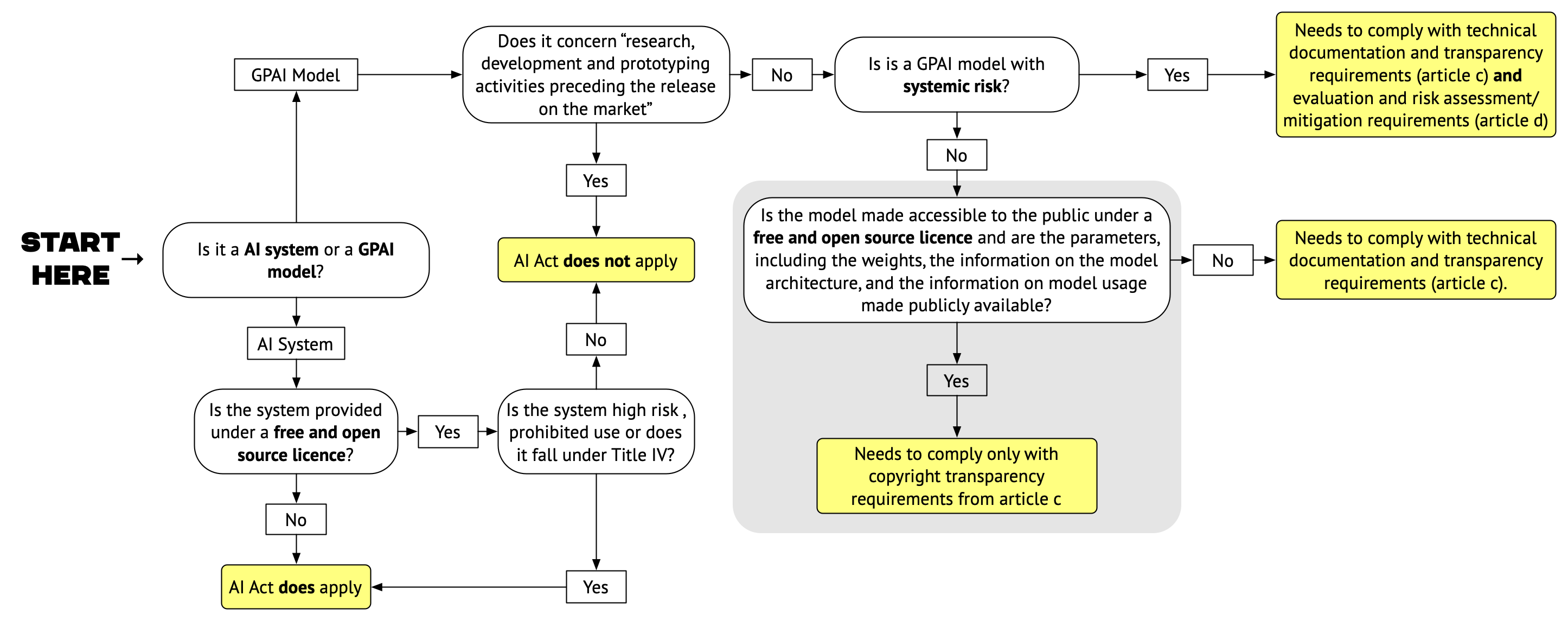
What does open source even mean in the AI context?
The exact definition of what constitutes open source AI is still very much the subject of discussion among practitioners from the open source community, license stewards, and other stakeholders. However, this did not prevent the EU legislators from taking a position that does provide some definitional clarity. According to the final compromise language, the exception from the provisions of the Act applies to “AI models that are made accessible to the public under a free and open-source license” and “whose parameters, including the weights, the information on the model architecture, and the information on model usage, are made publicly available.” The second set of conditions goes well beyond what is normally required by free and open source licenses and implies that those involved in drafting have a good understanding of AI development practices. Based on this understanding, they seem to have concluded that merely releasing a model under an open source license without providing access to other ingredients amounts to nothing more than “open washing.[2]”
Overview of open source provisions in the AI Act final compromise language with the problematic open source exemption for GPAI models highlighted in grey (click to enlarge)
Models vs Systems
So what does the above-mentioned exception for models released under free and open source licenses entail in detail? Here is where the approach becomes complicated.
On a very basic level, the AI Act distinguishes between AI systems (deployed AI systems and applications — think ChatGPT) and underlying General Purpose AI models (pre-trained models that are used as part of AI systems and applications — think GPT4).
With regard to AI systems, the final compromise provides fairly straightforward exceptions:
This Regulation shall not apply to AI systems provided under free and open source licences unless they are high-risk AI systems or an AI system that falls under Title II and IV.
This means that open source AI systems do not need to comply with the obligation of the Act unless they are high risk, are used for prohibited uses (Title II) or are intended for use in ways covered by Title IV of the Act (which does include systems intended to interact with natural persons and systems that generate or manipulate content). In these cases, the Act applies and they need to comply with those rules (for prohibited systems this means they cannot be used in the EU).
A tiered approach to GPAI models
With regards to GPAI models, the situation is a bit more complicated. The question if the Act should regulate the GPAI / foundation models or if the developers of such systems should simply be required to self-regulate, had been contentious among the legislators until the very end. The final compromise is based on a set of tiered obligations for GPAI models.
All GPAI models[3] must comply with basic obligations related to transparency, technical documentation, and compliance with the EU copyright framework.
In addition to this, GPAI models with systemic risks — initially defined as models for which “the cumulative amount of compute used for its training measured in floating point operations (FLOPs) is greater than 1025[4]” — must comply with additional obligations: They must perform model evaluations, assess and mitigate possible systemic risks, keep track of, document and report information about serious incidents, conduct and document adversarial testing, ensure an adequate level of cybersecurity protection and document and report about the energy consumption of the model.
Neither of these obligations arise for activities related to research, development and prototyping preceding the release of the model on the market.
This tiered approach is very similar to what we had proposed in a joint policy paper with open source AI developers and advocates before the summer. At first inspection, it looks like the final compromise text aligns with our principles. These principles involve having one set of obligations that applies to all models, focusing on documentation and transparency, which are inherent characteristics of well-run open source projects. Additionally, there should be another set of obligations that applies to more advanced models, that are often backed by entities capable of shouldering a higher compliance burden. We also suggested that research and development activities should not be covered by any of these obligations.
For some reason, the final version of the AI Act does not stop at implementing these principles, which would provide sufficient space for open source AI developers to operate in the EU. Instead, it goes one step further and bolts an explicit carve-out for open source models onto the tiered approach:
This Regulation shall not apply to AI models that are made accessible to the public under a free and open-source licence whose parameters, including the weights, the information on the model architecture, and the information on model usage, are made publicly available, except the obligations referred to in Articles C(1)(c) and(d), Article D.
In the above quote, Article D refers to the article dealing with the obligations for providers of general-purpose AI models with systemic risk. All models not meeting the “systemic risk threshold” are excepted from the transparency and documentation obligations but not from the obligations to comply with copyright law and to provide sufficiently detailed summaries of the content used for training the models (Articles C(1)(c) and(d) in the quote above).
In other words, the open source exemption is quite limited in scope. While it applies to the majority of GPAI models that do not pose systemic risk, it only exempts them from transparency and documentation requirements that should be considered best practices for any well-run open source project, and that are relatively easy to meet for models that meet the criteria established by the exemption.
The effect of this Frankenstein-like[5] combination of tiered obligations and a limited open source exemption is a situation where open source AI models can get away with being less transparent and less well-documented than proprietary GPAI models. This creates a strong incentive for actors seeking to avoid even the most basic transparency and documentation obligations to use open licenses while violating their spirit. It is hard to imagine that this is what the EU legislator intended. As the text of the Act is still undergoing technical clean-up, there is still an opportunity to better align the provisions dealing with open source AI. The best way to do this would be to limit the open source exception to AI systems while relying on the tiered approach to structure the obligations for GPAI models.

Footnotes
- The analysis below and the quotes are based on a document outlining the final compromise on General Purpose AI models that was published by various media outlets. The exact language is likely to change as the result of upcoming technical work by the co-legislators. Our analysis is provided for information purposes only. ^
- Most observers would consider the model weights to be an essential part of the model that should be included in the scope of the license. Merely making model weights publicly available is not sufficient for a model to be considered open source in any meaningful way.^
- The text makes it clear that to qualify as General Purpose, models must “display significant generality” and be “capable to competently perform a wide range of distinct tasks”. This seems to indicate that the provisions are aimed at pre-trained models and not and fine-tuned versions of such models that may be released by downstream developers.^
- Such purely technical thresholds have been criticized to only have a limited capacity to measure real-world impact. Fortunately, the AI Office and national regulators will have considerable latitude to update this threshold, including on the basis of non-quantitative criteria.^
- Both in the sense that it is assembled from disparate parts and in the sense that it will likely have problematic unintended impacts on the field.^




