Exploring commons-based approaches to machine learning and AI as public infrastructure
This line of work explores how AI technologies can be built and governed as public infrastructure. Today, concentrations of power in AI pose a challenge to public interest, as they make a broad range of activities dependent on a narrow group of monopolists. Our work concerns alternative, public AI systems and applications that can help address this challenge of concentrations of power in AI. We aim to demonstrate how more democratic, public interest oriented and purposeful systems can be designed, based on public AI principles and governance models.
The intersection between AI and openness is a key aspect of this work, as we explore commons-based approaches in AI. The nascent field of openly shared AI models lacks yet established norms for openly sharing data, compute, models, code. Addressing this gap requires governance mechanisms that uphold open sharing while addressing power imbalances and safeguarding digital rights. We are particularly interested in how various datasets can be shared in a purposeful and sustainable ways.
A new Europeana white paper makes the case for a European, public-interest approach to AI and asks the cultural heritage sector to help build it. It shows that Public AI is gaining traction among the institutions that steward Europe's cultural memory.
Europe's AI Gigafactories bet raises hard questions about whether public investment can deliver strategic autonomy or will end up subsidizing the very dependencies it seeks to overcome.
AI is becoming core European infrastructure. Yet non-European firms increasingly control it, concentrating investment, data, and talent. This creates risks for strategic autonomy, democratic decision-making, and the European social model. This brief proposes Public AI as an alternative.
The Digital Omnibus goes beyond technical fixes—the EU is finally acknowledging the Paradox of Open. Differentiated charging makes sense. Weakening standard licensing risks fragmentation.
This proposal outlines a European Books Data Commons—library-governed infrastructure providing centralized access to digitized books for AI training while strengthening digital sovereignty.
GEMA's lawsuit against OpenAI has reignited the debate about AI training and copyright. This post examines the relationship between AI training and the TDM exceptions.
Article 3 of the CDSM Directive allows EU research organizations and libraries to train AI models on copyrighted works. This analysis explores how this legal framework enables public AI development.
Wikimedia Switzerland, Open Future, and IMD Business School convened a roundtable in Lausanne to examine what AI means for the future of knowledge commons
The EU needs purposeful, open-source, and sustainable public AI—infrastructure that serves the public, not an AI-first race driven by dominant vendors.
Policymakers, academics, and representatives from journalism, culture, and civil society discuss how Europe can sustain original content in the age of generative AI.
In our submission, we acknowledge that the DMA’s framework already provides a basis for addressing competitive concerns in AI–particularly when AI systems are integrated into an existing Core Platform Service (CPS), such as search engines. However, to effectively regulate the evolving AI landscape, we propose to extend this approach.
We recommend two key changes. Firstly, foundation models should be designated as Core Platform Services, so that concentrations of power in AI can be better addressed. Secondly, bottlenecks related to data should be tackled through greater data transparency, mandatory third-party access to training data held by gatekeeper companies, and improved data portability between AI platforms.
The EU AI Office releases transparency template for AI training data—a step forward that falls short on delivering meaningful accountability. Our analysis reveals critical details missing.
On July 18, we submitted our response to the European Commission's consultation on the new Data Union Strategy. This new strategy builds upon the 2020 European Data Strategy, with the same goal of facilitating data sharing. Data availability, access and use is one of the key issues, and the Commission proposes a focus on the use of data for AI development.
Our submission proposes a European Data Commons as a balanced solution that supports economic value creation while protecting public interest objectives and fundamental rights. This is in line with our contributions to the previous strategy, which advocated for creating a Public Data Commons for business-to-government data sharing.
We emphasize that data use for AI development needs to be purposeful and sustainable. We also outline a data-driven pathway to AI development focused on public interest goals, and argue that a dedicated data infrastructure for generative AI development is needed.
We have signed an open letter urging the European Commission not to reopen the AI Act through the Digital Simplification package. Instead, we call for proper implementation and enforcement of the existing legislation.
Yesterday we submitted our response to the European Commission’s consultation on the proposed Cloud and AI Development Act. According to the Commission’s initial outline (which formed the basis for the consultation), the Act is intended to play a key role in advancing Europe’s digital sovereignty through investment in cloud and AI infrastructure.
Our response highlights two critical aspects for ensuring that this investment delivers genuine public value: procurement and sustainability.
We argue that public procurement should be used as a strategic tool to prioritise open, interoperable, and sovereign digital infrastructure — including support for community-based digital commons. At the same time, sustainability must be treated as a public responsibility, not left to voluntary industry initiatives. We call for strong regulatory safeguards to ensure that infrastructure investments align with Europe’s climate goals and democratic values.
This White Paper calls for a levy on commercial AI systems to fund public infrastructures and ensure a sustainable Digital Knowledge Commons in the generative AI era.
The newly released Common Pile by Eleuther.ai and Harvard Institutional Data Initiative's Institutional Books 1.0 demonstrate that Public Domain and openly licensed works can power robust AI development while addressing legal concerns.
The European Commission has been consulting on a new initiative, Apply AI, aimed at increasing the adoption of AI in key industrial sectors and the public sector. The public consultation has been running between 9 April and 4 June 2025, and its results will feed into a new communication from the Commission.
In our response, we argue that integrating AI technologies in the public sector and leading industrial sectors must prioritize the development of sovereign, public digital infrastructures for AI. This integration needs to happen in a purposeful manner, especially in sensitive sectors like public education or health. The strategy should also consider the risk of rushed deployment, and of large public investments going to private actors best positioned to meet the promise of swift deployment, without clear public benefits.
We outline three principles that should underpin the strategy: support and use of public AI infrastructure, support purposeful AI deployment, and ensure the sustainability of AI deployment in Europe.
Open Future and Bertelsmann Stiftung hosted an online event that brought together policymakers, industry representatives, and civil society to explore how Public AI can create more accessible and accountable technology.
Today's AI landscape is dominated by a few tech companies. This White Paper presents an alternative: Public AI systems built on transparency, democratic governance, and open access to critical infrastructure.
The EU's rush to simplify AI regulation risks weakening transparency rules. This regulatory shift threatens core principles needed for responsible AI development.
The AI Continent Action Plan needs a stronger vision of purposeful AI deployment if it wants to achieve more than just boost commercial AI development.
While the EU AI Act is the most significant opportunity to advance AI transparency, this analysis argues what information should be disclosed in a "sufficiently detailed summary", who it matters to, and why trade secrets cannot be used as an excuse to undermine transparency.
This report analyzes the development of Polish small language models and the ecosystem in which this happens. The case studies show alternatives to large commercial models that are built as Digital Commons, and can help fight concentrations of power in AI.
The Mozilla Foundation and Open Future co-hosted an event with policymakers, industry representatives, and civil society to explore how to make content used by AI more transparent.
Spawning has released PD12M, a fully open dataset consisting of 12.4 million image-caption pairs. The dataset exclusively consists of public domain and CC0 licensed images that have been obtained from Wikimedia Commons, a large number of cultural heritage organizations, and the iNaturalist website. From the paper accompanying the release:
We present Public Domain 12M (PD12M), a dataset of 12.4 million high-quality public domain and CC0-licensed images with synthetic captions, designed for training text-to-image models. PD12M is the largest public domain image-text dataset to date, with sufficient size to train foundation models while minimizing copyright concerns. Through the Source.Plus platform, we also introduce novel, community-driven dataset governance mechanisms that reduce harm and support reproducibility over time.
The release of PD12M is remarkable not only given the size of the fully open dataset but also because of the holistic approach that Spawning has taken. Via the source.plus platform, Spawning provides community-based governance mechanisms. In addition, the platform also provides an exemplary level of transparency regarding the sources of the images included in the dataset.
The release of PD12M is exciting not only because it builds on our ideas for a public data commons but also because Spawning sees the release of the dataset as a first step towards offering a foundational public domain image model with no IP concerns, that will help artists to fine-tune, and own, their own models on their own terms.
This week, the Open Source Initiative released its definition of open source AI. This analysis considers its significance as a standard, its limitations, and the need for a broader community norm.
This video provocation, presented at the European Heritage Hub Forum, focuses on AI systems' implications for the role of cultural heritage institutions.
The Landgericht Hamburg's decision to allow LAION to include a photographer's image in the LAION-5B training dataset empowers non-profit providers of public training datasets, which play a critical role in making AI training more transparent.
This policy brief considers open-source AI as a digital public good and provides recommendations for progressing toward AI democratization and accelerating the attainment of the SDGs.
We hope that this revised blueprint will help inform the AI Office's work and serve as a valuable contribution to the consultations on the Code of Practice, outlining rules for general-purpose AI providers.
At the June AI and the Commons community call, we discussed the heritage sector’s relationship to AI (generative and analytical). Our guests were Dr. Mathilde Pavis, an expert in intellectual property law, ethics, and new technologies, and Mike Weinberg, Executive Director of NYU's Engelberg Center for Innovation Law and Policy.
If you are interested in learning more about the outcomes of the Alignment Assembly process and would like to participate in further discussions on this topic, register to join the report's online launch.
This paper and the accompanying blueprint of the transparency template that the AI office is tasked to develop is a collaborative effort of Open Future and Mozilla Foundation, drawing on input from experts.
This report captures learnings from the Alignment Assembly on AI and the Commons, a six-week online deliberation of open movement activists, creators, and organizations about regulating generative AI.
Last week, Spawning launched source.plus, a platform for “curating, enriching and downloading non-infringing media collections in bulk for AI training.” This is a significant step in addressing a host of issues with AI training datasets, such as LAION or face recognition training datasets.
The aim of this experimental platform is to demonstrate that licensed content is not the only viable solution:
This means the most conscientious developers and most affected communities are often on the sidelines of this rapidly developing field, whereas these are the very groups that need to be steering its evolution, and they too should be able to benefit from participation with AI.
Its real value lies not just in the volume of aggregated media files but in how they are curated and governed. It is an interface to established collections, it introduces additional mechanisms – many of which we have proposed in our recent white paper, Commons-based governance of data sets for AI training. For example, source.plus is the first collection to offer an “opt-out” mechanism. Spawning is also planning to introduce value-sharing mechanisms, including paid collections of in-copyright works and a donation mechanism that supports cultural heritage institutions.
The brief outlines a policy agenda that addresses concentrations of power in AI through policies supporting democratic governance of these technologies. It was written together with other organizations by invitation from Think7, the think tank of the Italian G7 Presidency.
At our April AI and the Commons community call, we heard from Pierre-Carl Langlais who talked about ways in which generative AI models can be designed and built as a Commons.
This white paper describes ways of building a books data commons: a responsibly designed, broadly accessible data set of digitized books to be used in training AI models.
During the last AI and the Commons call, we spoke to Tim Davies about including the public in AI governance. In his presentation, Tim talked about Connected by Data’s People’s Panel on AI.
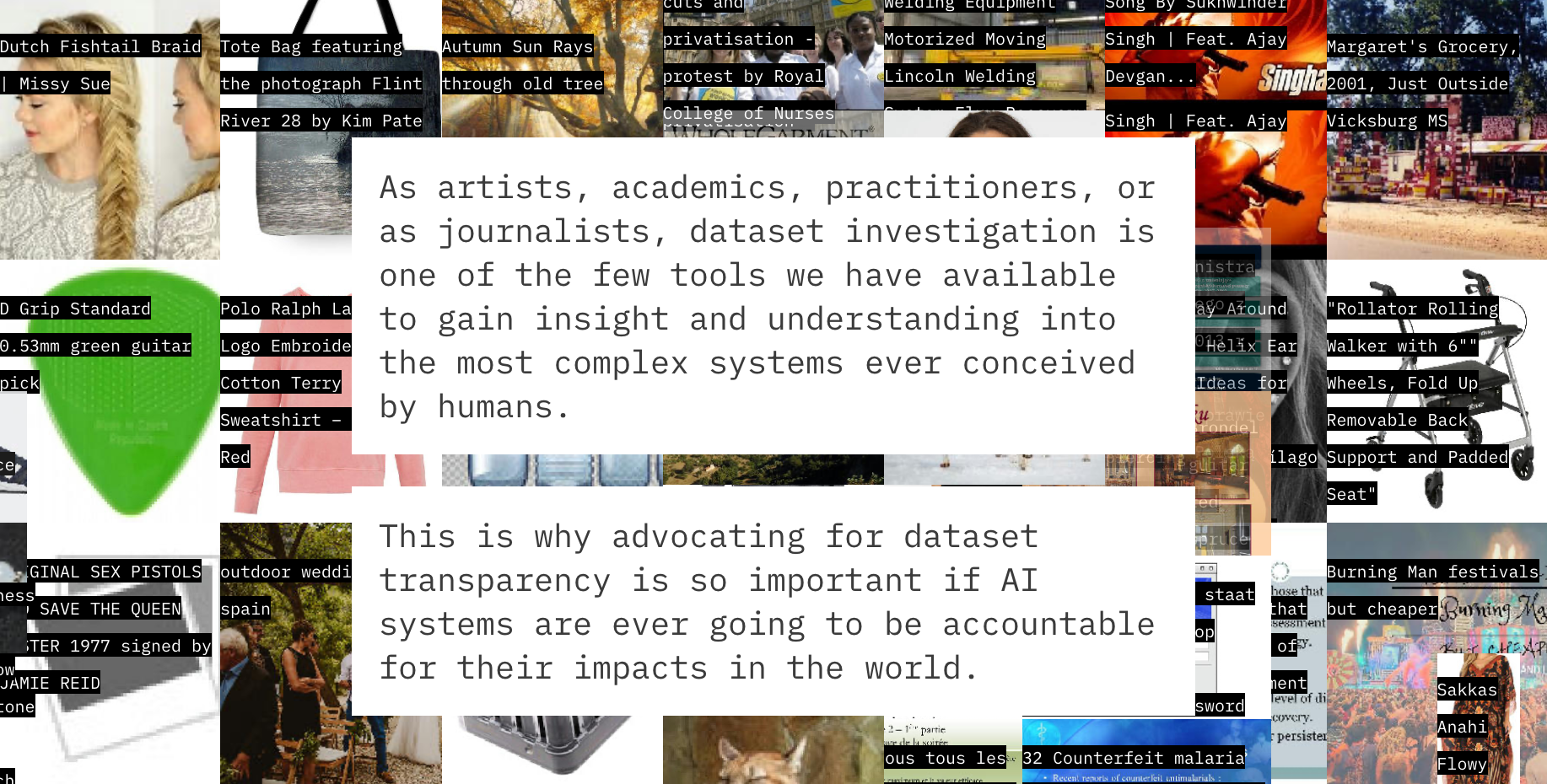
Researchers at Knowing Machines have published Models all the way down, a visual investigation that takes a detailed look at the construction of the LAION 5B dataset "to better understand its contents, implications, and entanglements.” The investigation provides detailed insight into the internal structure and strategies used to build one of the largest and most influential training datasets used to train the current crop of image generation models. Among other things, the researchers show that the model's curators relied heavily on algorithmic selection to assemble the model, and as a result…
…there is a circularity inherent to the authoring of AI training sets. [...] Because they need to be so large, their construction necessarily involves the use of other models, which themselves were trained on algorithmically curated training sets. [...] There are models on top of models, and trainings sets on top of training sets. Omissions and biases and blind spots from these stacked-up models and training sets shape all of the resulting new models and new training sets.
One of the key takeaways from the researchers (who, for all their critical observations, give LAION credit for releasing the dataset as open data) is that we need more dataset transparency to understand the structural configuration of today's generative AI systems, which is very much in line with what we’ve been advocating for in the context of the AI Act and will continue to push for in the implementation of the Act.
A group of AI researchers coordinated by the French start-up Pleias wants to challenge the belief that you need copyrighted materials to train an LLM that competes with the models developed by leading AI companies. Yesterday, they released what has been dubbed the largest open AI training data set consisting entirely of public-domain texts. The collection is called “Common Corpus” and is available on Hugging Face for download. The resource is multilingual – besides English, it includes the largest open collections in French, German, Spanish, Dutch, and Italian, as well as collections for other languages.
Training data is a key resource for developing AI systems. Until very recently, it was commonly believed that LLMs, such as those behind popular services such as ChatGPT or Bard, could not be trained without relying on copyrighted content. If this is the case, access to high-quality data may continue to be a significant barrier for independent AI developers seeking to compete in the LLM market.
Datasets consisting only of public domain texts have significant limitations, the most important being that they miss more contemporary information because they are comprised of historical sources or older publications where copyrights have already expired. It remains to be seen whether public domain datasets can indeed compete with datasets containing more contemporary content that is protected by copyright.
There is an urgent need to address the issue and set a clear standard for transparency with regard to AI training and access to training datasets. The European policymakers avoided answering the questions that could help ensure openness in the context of AI development.
At our first 2024 AI and the Commons Community Call, we were joined by Eryk Salvaggio, an interdisciplinary researcher, lecturer, and artist who works with digital media and AI.
Last week, the Commission published the AI Innovation Package to support Artificial Intelligence startups and SMEs. The measures listed in the package include facilitating access to AI-focused supercomputers, which is expected to help expand the use of AI to a wide range of users, including European start-ups and SMEs. An article in Science|Business rightly pointed out that the plan outlined by the Commission suggests that it is pinning its hopes on private companies to keep the EU competitive in AI.
Putting faith in private actors is not sufficient. The way to address the imbalance of power and market concentration must also include investing in the development of systems that serve society and have the best interests of people and the planet at their core. At the moment, it doesn't seem that this approach will be implemented in the field of AI. Whether we can expect any efforts to create a public option for AI in Europe remains to be seen. Some public interests, such as ensuring diversity and transparency in the datasets that train AI models, are simply not always aligned with the interests of corporations who might favor the fastest and cheapest solutions. This is where public authorities, civil society and the large communities of scientists and practitioners working on AI in Europe have a role to play.
Science | Business reported that German Research Minister Bettina Stark-Watzinger believes that "no state or association of states can match the investments made by large corporations like Microsoft or Google with public investments.”
This suggests that the German government throws in the towel and assumes that private actors are equipped and have the intention to develop digital services that serve the public interest and allow people to enjoy their fundamental rights.This approach is somewhat disappointing, and given the example of private social media platforms that fail to fulfill the role of digital public spaces,, it does not appear to be appropriate. To put it simply, without public funding, European society won't get AI that serves the public.
Open Future is hosting an asynchronous, virtual alignment assembly for the open movement to explore principles and considerations for regulating generative AI. We hope to reach 500 participants, spread across different fields of open and coming from different regions of the world.
To discuss the work presented in “Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI," we have invited its authors to join our monthly community calls, which explore the intersection of AI and the Commons.
As a part of exploring the relationship between generative AI systems and the commons, we have been looking closely at the approach taken on Wikipedia.
The brief outlines the current evidence on the risks of open foundation models (FMs) and offers some recommendations for policymakers on how to think about the risks of open FMs. The brief argues that open FMs - defined by the authors as "models with widely available weights" — "provide significant benefits by combating market concentration, catalyzing innovation, and improving transparency." The authors therefore conclude that "policymakers should explicitly consider the potential unintended consequences of AI regulation on the vibrant innovation ecosystem around open foundation models."
The policy brief also points out that despite widespread concern about the dangers of open foundation models that has dominated policy discussions, "the existing evidence on the marginal risk of open foundation models remains quite limited. The key questions for understanding their impact are the risks posed by open models relative to the risks posed by other models (the marginal risk):
To what extent do open endowment models increase risk relative to (a) closed endowment models or (b) pre-existing technologies such as search engines?
Coming a few days after the final compromise on the EU AI Act, the policy brief provides further support for the AI Act's approach of providing targeted exemptions for open (source) AI developers. The final compromise on the AI Act sidesteps policies - liability for downstream harm, licensing of model developers - that the authors of the policy brief see as particularly problematic for open AI developers. As we argued in our analysis of the Act, the overall approach to open source AI development in the AI Act is quite sound, although there is still room for improvement by getting some of the details of the transparency obligations right.
Late last week, the European Commission, the Member States, and the European Parliament reached a deal on the AI Act. The current compromise is a combination of tiered obligations and a limited open source exemption which creates a situation where open source AI models can get away with being less transparent and less well-documented than proprietary GPAI models.
This opinion takes a closer look at how the Falcon 180B model is licensed and is a part of our exploration of the emergent standards for the sharing of AI models.
As part of the CSCW 2023 conference, Alek co-organized a workshop titled “Can Licensing Mitigate the Negative Implications of Commercial Web Scraping?”. Representatives of several research institutions, Hugging Face, Creative Commons, RAIL, and Hippo AI participated in the conversation. You can read the short paper outlining the ideas behind the workshop in the ACM digital library.
Some experts believe that open-sourcing AI increases the risk of malicious use. In this opinion, we argue that calls for regulators to intervene and limit the possibility of open-sourcing AI models must consider the impact on freedom of expression.
Zuzanna and Alek gave a talk on commons-based governance of AI datasets, as part of this year’s Deep Dive on AI webinar series, organized by the Open Source Initiative. The webinars are part of OSI’s initiative to define a new standard for Open Source AI systems, in which we are participating. The talk highlighted the importance of strong standards for data sharing that should be part of a community standard for open source AI. You can watch the video here.
We agree with Widder, West, and Whittaker that openness alone will not democratize AI. However, it is clear to us that any alternative to current Big Tech-driven AI must be, among other things, open.
In this analysis, I review the Llama 2 release strategy and show its non-compliance with the open-source standard. Furthermore, I explain how this case demonstrates the need for more robust governance that mandates training data transparency.
The AI Act should allow for proportional obligations in the case of open source projects while creating strong guardrails to ensure they are not exploited to hide from legitimate regulatory scrutiny.
The AI Act should provide clarity on the criteria by which a project will be judged to determine whether it has crossed the “commercialization” threshold, including revenue.
In a third recommendation, Mozilla highlights the importance of definitional clarity when it comes to regulating open source AI systems. Here Mozilla suggests maintaining a strict definition (that would exclude newer licenses like the RAIL family of licenses) and clarifying which components would need to be licensed under an open license for a system to be considered to be an open source AI system. According to Mozilla this should indicatively apply to models, weights and training data.
Today — together with Hugging Face, Eleuther.ai, LAION, GitHub, and Creative Commons, we publish a statement on Supporting Open Source and Open Science in the EU AI Act. We strongly believe that open source and open science are the building blocks of trustworthy AI and should be promoted in the EU.
We need a more holistic approach that considers how machine learning technologies impact Wikimedia — changes to editing, disintermediation of users, and governance of free knowledge as a resource used in AI training. These changes call for an overall strategy that balances the need to protect the organization from negative impact and harms with the need to deploy new technologies in productive ways to help build the digital commons.
This article examines an example from the global women's rights movement of how organizations and institutions support local actors to participate in transnational AI governance and challenge top-down structures and mechanisms.
Today, the European Parliament's IMCO and LIBE committees adopted their joint report on the proposed AI Act. The text includes additional safeguards for fundamental rights and an overall more cautious approach to AI. In this post, we provide an in-depth analysis of the implications of the text for open source AI development.
The following piece is the first part of a case study on how Wikipedia is positioned to address the challenges of open AI development. It spells out the general argument, which will be followed by more specific suggestions on how a wikiAI mission could look like.
Establishing a regulatory framework that achieves the dual objectives of protecting open-source AI systems and mitigating risks of potential harm is a critical imperative for the European Union. Especially since open-source, publicly supported AI systems are crucial digital public infrastructures that would ensure Europe’s sovereignty.
The European Union's upcoming AI Act will require adequate standards to become fully operational, and much work is required to ensure that the standardization process does not conflict with the Act's inclusion and transparency objectives.
The process will be led by the European Committee for Standardization (CEN) and the European Committee for Electrotechnical Standardization (CENELEC). In the past, they have been criticized for their secrecy and lack of transparency. The standards must be made public, but some fear that the private sector will have too much control over the process, which could have an impact on human rights. The standards' nature and scope will also have geopolitical implications, with some calling for greater international cooperation.
Standards will be essential in enforcing the EU's AI legislation, and CEN-CENELEC will have just two years to formulate and agree on a series of AI standards.
The LAION proposal calls for a public research facility capable of building large-scale artificial intelligence models. It offers an alternative to corporate development of AI, in which responsible use is ensured in open source environments through the involvement of democratically elected institutions.
The rapid advancements in AI challenge the concept of openness on the internet, as companies use publicly available data to their advantage, frequently disregarding the concerns and welfare of other parties, such as artists and content creators, and the impacts of the tools they make available for use. There is a growing realization that the […]
The Future of Life Institute published an open letter asking for a moratorium on generative AI development. Yet social harms caused by AI will not be addressed in this way. Instead, commons-based governance of existing AI systems is needed.
Natali Helberger and Nicholas Diakopoulos have published an article titled "ChatGPT and the AI Act" in the Internet Policy Review. The article argues that the AI Act’s risk-based approach is not suitable for regulating generative AI due to two characteristics of such systems: their scale and broad context of use. These characteristics make it challenging to regulate them based on clear distinctions of risk and no-risk categories.
The article is relevant to us in the context of open source, general-purpose AI systems, and their potential regulation.
Helberger and Diakopoulos propose looking for inspiration in the Digital Services Act (DSA), which lays down obligations on mitigating systemic risks. A similar argument was made by Philipp Hacker, Andreas Engel, and Theresa List in their analysis.
Interestingly, the authors also point out that providers of generative AI models are currently making efforts to define risky or prohibited uses through contractual clauses. While they argue that “a complex system of private ordering could defy the broader purpose of the AI Act to promote legal certainty, foreseeability, and standardisation,” it is worth considering how regulation and private ordering (through RAIL licenses, which we previously analyzed) can contribute to the overall governance of these models.
The Collective Intelligence Project has published a new working paper by Saffron Huang and Divya Siddarth that discusses the impact of Generative Foundation Models (GFMs) on the digital commons. One of the key concerns raised by the authors is that GFMs are largely extractive in their relationship to the Digital Commons:
The dependence of GFMs on digital commons has economic implications: much of the value comes from the commons, but the profits of the models and their applications may be disproportionately captured by those creating GFMs and associated products, rather than going back into enriching the commons. Some of the trained models have been open-sourced, some are available through paid APIs (such as OpenAI’s GPT-3 and other models), but many are proprietary and commercialized. It is likely that users will capture economic surplus from using GFM products, and some of them will have contributed to the commons, but there is still a question of whether there are obligations to directly compensate either the commons or those who contributed to it.In response, the paper identifies three proposals for dealing with the risks that GFMs pose to the commons.
In response, the paper identifies three proposals for dealing with the risks that GFMs pose to the commons. Read the full paper here:
The RAIL licenses are gaining ground, but permissive sharing is still the prominent norm governing the sharing of ML models on huggingface.co. This analysis aims at understanding how licenses are used by developers making ML model-related code and or data publicly available.
None of the approaches dealing with open source AI systems in the AI Act address the concerns related to chilling effects on open source AI development so far. The Parliament still has the opportunity to address these concerns without jeopardizing the AI Act’s overall regulatory objective by leveraging on the inherent transparency of open source, writes Paul Keller.
The launch of BLOOM, an open language model capable of generating text, and the related RAIL open licenses by BigScience, together with the launch of Stable Diffusion, a text-to-image language, shows that a new approach to open licensing is emerging. In Notes on BLOOM, RAIL, and openness of AI, Alek outlines the challenges to established ways of understanding open faced by AI researchers, as they aim to enforce their vision of not just open, but also responsible AI.
Instead of analyzing the functioning of image generators through the lens of copyright, we should ask ourselves a normative question: Why should we want that copyright applies to the visual output of these generators?